Posted inPhármacoLόgos
Confabulazioni e allucinazioni delle macchine del linguaggio
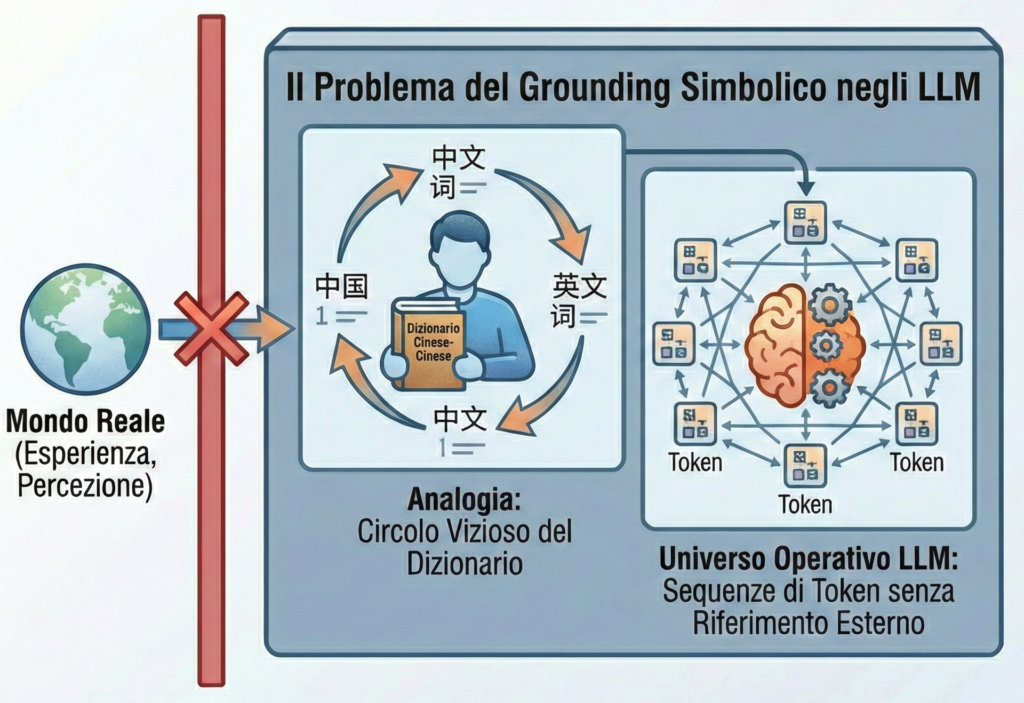
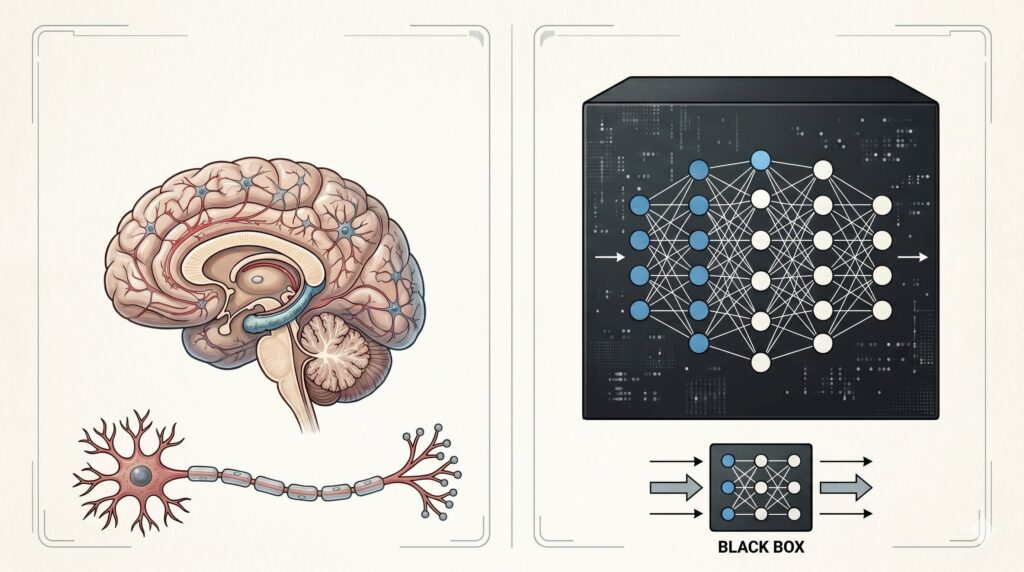
Sull’ultimo numero di Giugno 2026 del NEJM AI ho pubblicato una lettera dal titolo Borrowing Carefully: The Words We Choose for AI Errors Shape Clinical Trust. In estrema sintesi, la tesi che sostengo è questa: quando un modello linguistico produce un’informazione falsa, non solo non sta in senso stretto “allucinando”, ma anzi il termine è molto fuorviante. Dal momento che in sanità le parole con cui descriviamo gli errori influenzano il modo in cui medici e pazienti si fidano del sistema, vale la pena di approfondire la questione. La rivista, per ragioni di spazio, ha pubblicato una versione ridotta del testo che avevo proposto, perciò riprendo qui l’argomento per intero, in forma più distesa.