Sul numero del 2 febbraio 2026 di Nature, Eddy Keming Chen, Mikhail Belkin, Leon Bergen e David Danks (tutti della University of California, San Diego) hanno firmato un Comment dal titolo “Does AI already have human-level intelligence? The evidence is clear“. Secondo gli autori, la visione di un’intelligenza artificiale paragonabile a quella umana, formulata da Turing nel 1950, sarebbe ormai una realtà, e a riconoscerlo basterebbe uno sguardo libero da timore e da entusiasmo.
L’argomento, ridotto all’essenziale, procede nel seguente modo.
I grandi modelli linguistici attuali risolvono problemi matematici nuovi, superano esami professionali in domini diversi, generano codice funzionante, esibiscono trasferimento di competenze fra ambiti distanti. Applicando a loro lo stesso criterio inferenziale con cui attribuiamo intelligenza ad altri esseri umani, cioè un’inferenza alla migliore spiegazione a partire dal comportamento osservato, dovremmo concludere che anche questi sistemi sono, in qualche senso significativo, intelligenti. Mente umana e modello linguistico, secondo questa lettura, sarebbero due sistemi confrontabili: due scatole nere giudicabili in base a ciò che producono.
Io ritengo però che la simmetria su cui poggia l’argomento sia fittizia, e l’ho sostenuto nella lettera di risposta pubblicata su Nature ad aprile, AI and the human mind: only one is a black box: mente umana e LLM non sono due oggetti dello stesso genere epistemico, e trattarli come tali confonde due situazioni conoscitive molto diverse.
Sulla dissimmetria epistemica tra mente umana e modelli linguistici
L’intelligenza umana è un fenomeno naturale. Non abbiamo una conoscenza a priori di come funzioni. È a partire da essa che il concetto stesso di intelligenza è stato costruito, prima dalla filosofia, poi dalla psicologia e infine, più recentemente, dalle scienze cognitive. I meccanismi generativi della mente umana non sono ancora pienamente compresi: come dal sostrato neurale emergano comprensione, giudizio, intenzionalità, in dettaglio, non lo sappiamo. Quando attribuiamo intelligenza a un essere umano, lo facciamo in assenza di un’altra spiegazione disponibile per il suo comportamento cognitivo. L’attribuzione è la spiegazione migliore di cui disponiamo, e per questo l’inferenza alla migliore spiegazione è legittima.
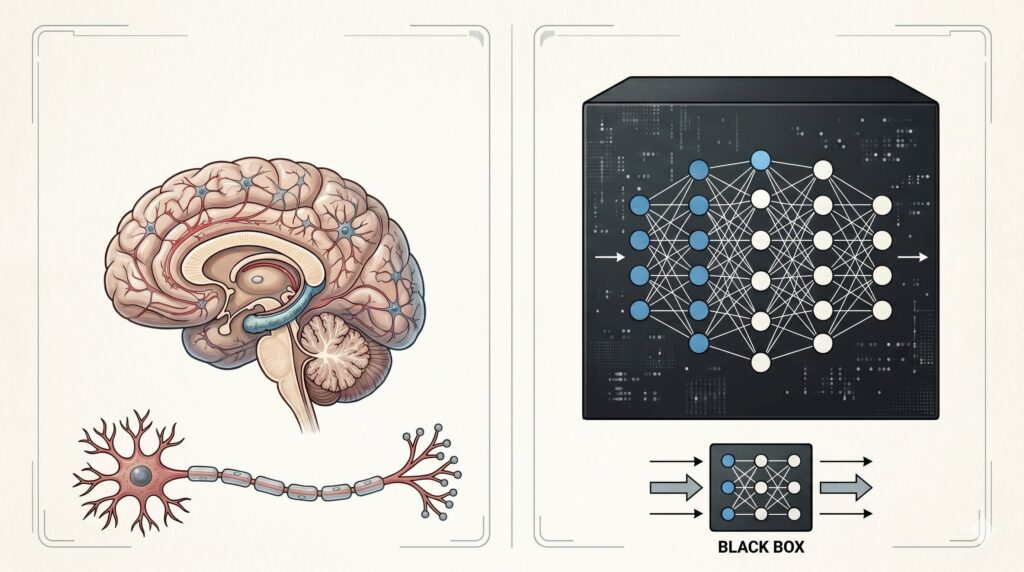
Gli LLM sono in una situazione opposta. Sono sistemi progettati e costruiti, non fenomeni naturali da decifrare. Il loro principio di funzionamento, ottimizzazione statistica della predizione del prossimo token, è noto. La loro complessità interna è enorme, e questo rende spesso difficile ricostruire passo per passo la traiettoria che produce un output specifico, ma complessità non equivale a opacità di principio. Un sistema di cui conosciamo l’architettura e la funzione obiettivo è complesso, non misterioso. Chiamarlo black box nello stesso senso in cui lo è la mente umana appiattisce una distinzione che invece dovremmo tenere sempre presente.
Nel caso umano l’attribuzione di intelligenza è giustificata perché non disponiamo (né abbiamo bisogno) di una spiegazione alternativa adeguata del comportamento osservato. Nel caso degli LLM una spiegazione sufficiente esiste già, ed è il meccanismo generativo stesso: produzione di sequenze coerenti per ottimizzazione statistica su un’enorme base di testi. Per inferire qualcosa di più (in particolare comprensione o intelligenza in senso forte) occorrerebbe mostrare che il comportamento cognitivo del sistema non è interamente riconducibile a quel meccanismo. Non è una prova impossibile in linea di principio. Ma è una prova che, allo stato attuale, non è stata fornita (né, in realtà, è ad oggi necessaria).
Il fatto che non conosciamo nei minimi dettagli come funzioni il pensiero umano non ci autorizza a concludere che non sappiamo come funzionano dei sistemi che abbiamo costruito noi stessi.
Due forme di opacità
Nell’uso ingegneristico, il concetto di “scatola nera” designa un sistema di cui si osservano gli ingressi e le uscite senza poter esaminare in dettaglio i passaggi interni che li collegano. Si tratta di una nozione operativa, riferita più alla nostra capacità di ispezione, che alla natura intrinseca del sistema. Una scatola nera in questo senso può tornare ispezionabile quando si dispone degli strumenti adeguati, e il fatto che oggi non si riesca a tracciare l’attivazione di ciascuno dei miliardi di parametri di un LLM è una limitazione pratica, non una proprietà del sistema in quanto tale.
L’opacità della mente umana ha tutt’altra natura. Non riguarda soltanto la mancanza di una mappa neurale completa dei processi cognitivi: anche disponendone, resterebbe aperto il problema di come da quei processi emerga ciò che chiamiamo comprensione, giudizio, intenzione, esperienza in prima persona. Un esempio classico di questa problematica è la distinzione che David Chalmers ha tracciato fra “problemi facili” e “problema difficile” della coscienza. I meccanismi funzionali della cognizione ricadono in un dominio in linea di principio aggredibile dalle neuroscienze. Il carattere qualitativo dell’esperienza, ciò che si prova a vedere, ricordare, decidere, invece non può essere semplicemente saturato dalla descrizione funzionale, per quanto dettagliata essa diventi. L’opacità della mente non è tanto una mancanza di accesso che la ricerca potrà ridurre col tempo, quanto piuttosto una resistenza concettuale che caratterizza il modo stesso in cui costruiamo la spiegazione.
Quando si dice che mente umana e LLM sono entrambi “black boxes”, si tengono insieme due cose che hanno in comune solo la metafora. Il modello linguistico è opaco solo in senso ingegneristico: sappiamo cosa fa, e nei suoi tratti generali sappiamo come lo fa, ma fatichiamo a ricostruire perché in una specifica occasione abbia prodotto una specifica sequenza. La mente è opaca in un senso filosoficamente più radicale: non sappiamo, in nessun senso davvero soddisfacente, come dal cervello sorga la cognizione. Le due opacità appartengono a piani diversi e non legittimano lo stesso tipo di inferenza. La prima è un limite operativo di un sistema noto, la seconda rappresenta una problematica centrale che la ricerca non è ancora in grado di affrontare.
L’asimmetria nella spiegazione
L’inferenza alla migliore spiegazione, nella formulazione classica che si fa risalire a Harman, non consiste semplicemente nel saltare dall’osservazione di un comportamento all’attribuzione della causa che ci suggestiona di più, bensì nel selezionare, fra le ipotesi disponibili, quella che rende meglio conto del fenomeno osservato in base a criteri di parsimonia, coerenza con le conoscenze pregresse e ampiezza esplicativa. Senza una concorrenza di ipotesi, non ha senso dire che scegliamo la migliore.
Nel caso degli LLM la concorrenza esiste, ed è chiaramente asimmetrica. Si può ipotizzare che il sistema produca testo coerente perché in qualche senso comprende ciò di cui parla. Oppure si può ipotizzare che il sistema produca testo coerente perché è stato addestrato a generare la continuazione statisticamente più probabile su una base testuale massiva, e che questa procedura, per ragioni ricostruibili architetturalmente, dia esiti che la nostra mente legge come comprensione. La seconda ipotesi è documentata e ben fondata sulla letteratura tecnica degli ultimi anni. Per sostenere la prima ipotesi occorrerebbe mostrare che essa spiega qualcosa che la seconda non riesce a spiegare. Finché questa eccedenza esplicativa non viene evidenziata, l’inferenza alla migliore spiegazione si conclude a favore dell’ipotesi più parsimoniosa, non di quella più suggestiva.
Nel caso della mente umana questa concorrenza non si pone alla stessa maniera. Non disponiamo di una descrizione meccanicistica del cervello che renda conto del comportamento cognitivo senza ricorrere al lessico mentalistico, e perciò l’attribuzione di intelligenza non compete con un’alternativa che la renda superflua: la ipotizziamo perché senza di essa il fenomeno resta non spiegato. Le due situazioni epistemiche, ancora una volta, non si sovrappongono. In un caso l’attribuzione di intelligenza colma una lacuna esplicativa che non sappiamo altrimenti riempire; nell’altro si aggiunge a una spiegazione che regge da sola, e per essere mantenuta dovrebbe mostrare di aggiungere qualcosa.
La metafora della scatola nera, applicata uniformemente a mente e modello, orienta l’attenzione verso ciò che non riusciamo a osservare e la distoglie da ciò che distingue le due situazioni. Nel caso della mente, l’assenza di una spiegazione alternativa adeguata è una condizione conoscitiva reale; nel caso degli LLM, la spiegazione esiste, è nota e funzionante, e qualsiasi attributo aggiuntivo dovrebbe mostrare cosa aggiunge a quanto già spiegato.
Riferimenti
- Vannacci A. AI and the human mind: only one is a black box. Nature 652, 534 (9 aprile 2026). https://doi.org/10.1038/d41586-026-01094-7
- Chen EK, Belkin M, Bergen L, Danks D. Does AI already have human-level intelligence? The evidence is clear. Nature 650, 36–40 (2 febbraio 2026). https://doi.org/10.1038/d41586-026-00285-6