Quando si chiede a un modello linguistico di spiegare una procedura clinica, di valutare una sentenza, di ricostruire un argomento filosofico, o in genere di esprimere un giudizio su qualunque questione, la risposta ha quasi sempre una forma ben riconoscibile: presenta una tesi, introduce distinzioni, articola passaggi causali, conclude. La superficie del testo è quella del ragionamento competente, anche se in realtà esiste una discrepanza fra il processo generativo dei sistemi LLM e l’apparenza del loro output.
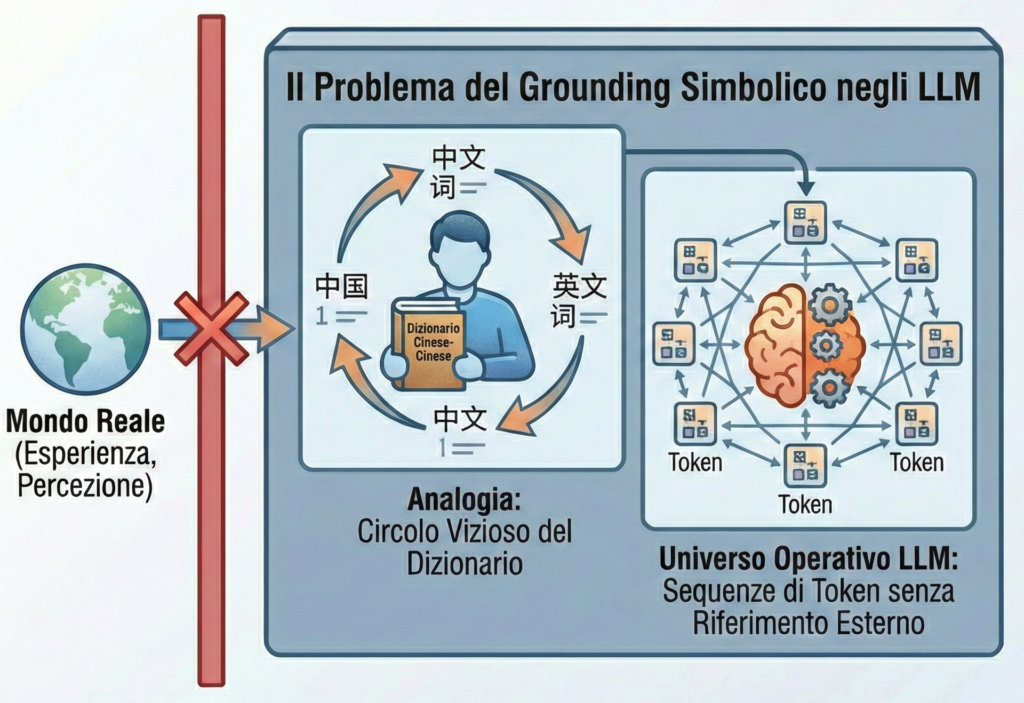
Sul versante del processo, il modello esegue un’operazione di tipo stocastico, ovvero, data una sequenza di input, il sistema calcola le distribuzioni di probabilità apprese durante l’addestramento e produce, token dopo token, la continuazione più plausibile. Il modello non possiede alcuna rappresentazione di significato, non ha alcun accesso ai truthmaker (ciò che, nel mondo, rende vera una proposizione che sto affermando) e di fatto non è in grado di esercitare alcuna distinzione interna fra ciò che è vero e ciò che è falso.
Sul versante della superficie, però, il testo che leggiamo riproduce la struttura tipica dell’inferenza abduttiva: espone premesse, valuta ipotesi, propone conclusioni accompagnate da giustificazioni. Floridi e colleghi parlano però in questo caso di apparenza abduttiva, e descrivono più precisamente questa operazione come zeroth-order abduction. Quando funziona, l’output è accurato, quando non funziona, il sistema confabula, ma lo fa con la stessa eloquenza di quando funziona, costruendo asserzioni false ma circostanziate, fonti bibliografiche inesistenti, ricostruzioni storiche inventate nei dettagli. La forma della spiegazione resta indistinguibile nei due casi.
In un articolo in corso di revisione, disponibile come prepint su SSRN, ho parlato della illusione epistemica, cioè il fenomeno per cui un output linguisticamente plausibile viene automaticamente percepito come portatore di conoscenza (una forma di illusione epistemica è quella recentemente definita col termine epistemia dal gruppo di Walter Quattrociocchi, dell’Università “La Sapienza” di Roma). Dal punto di vista analitico, questa illusione si presta ad una valutazione relazionale: essa emerge dall’incontro fra un’architettura che replica la superficie formale del discorso epistemicamente competente e una mente umana predisposta a interpretare automaticamente la coerenza linguistica come un segnale di affidabilità, a causa della disposizione che la scienza cognitiva ha descritto come intentional stance (Dennett 1988). Le forme principali in cui l’illusione si manifesta sono la trasparenza apparente della risposta, l’indistinguibilità testuale fra produzione umana e artificiale (documentata ad esempio da Jones e Bergen sui paradigmi turinghiani, in cui ormai i valutatori umani non discriminano più in modo affidabile le risposte di un modello avanzato da quelle di un interlocutore umano), e la sycophancy, l’effetto sistematico causato dal reinforcement learning from human feedback che premia la plausibilità relazionale a scapito della correttezza. La sycophancy in particolare è particolarmente insidiosa, perché trasforma l’illusione in un circuito attivo di rinforzo, in cui le credenze (potenzialmente sbagliate) dell’utente vengono confermate da una fonte esterna apparentemente autorevole.
Il quadro teorico in cui colloco questa nozione è costruito su due assi.
- Sul versante della verità, articolo tre livelli progressivamente più esigenti: plausibilità sintattica (la conformità formale alle regole del discorso), soddisfazione strutturale in senso tarskiano (la verità relativa a un modello), ancoraggio ontologico (l’esistenza di un truthmaker nel mondo). Gli LLM soddisfano il primo livello sistematicamente (è ciò per cui sono ottimizzati), il secondo accidentalmente (quando la plausibilità statistica coincide con la verità fattuale), il terzo mai.
- Sul versante della conoscenza, seguendo Harnad, distinguo functional beliefs e phenomenally qualified beliefs: i primi sono stati interni che, in virtù del loro ruolo causale, contribuiscono a generare l’output di un sistema (biologico o artificiale); i secondi sono accompagnati da esperienza qualitativa e dalla capacità del soggetto di valutarli alla luce di ragioni. Gli LLM possiedono plausibilmente qualcosa di assimilabile ai primi, ma niente di paragonabile ai secondi. Anche quando il loro output è vero, la condizione doxastica della definizione classica di conoscenza è soddisfatta solo in senso funzionale e derivato.
Una conseguenza dell’analisi tocca direttamente anche la questione della Intelligenza Artificiale Generale (di cui abbiamo parlato qui). In estrema sintesi, Chen e colleghi, in un articolo recente apparso su Nature, sostengono che gli LLM esibirebbero già un’intelligenza generale di livello umano, sulla base di un’inferenza alla migliore spiegazione condotta a partire dal comportamento osservato. L’argomento però riposa su un’asimmetria epistemica che vale la pena nominare. Nel caso della mente umana, l’attribuzione di comprensione è una inferenza necessaria, perché i meccanismi generativi della cognizione non sono ancora stati identificati (ammesso che mai lo siano), perciò non disponiamo di un’alternativa esplicativa al fatto di trattare l’interlocutore come un soggetto che comprende. Nel caso degli LLM, l’architettura invece è nota, e il meccanismo generativo è sufficiente a rendere conto degli output. L’attribuzione di comprensione, in questo caso, è un’inferenza che eccede ciò che il meccanismo fornisce.
Nella tassonomia più ampia che sviluppo nel lavoro da cui questa pubblicazione deriva, l’illusione epistemica è alla base di altri due problemi nella nostra relazione con la IA generativa: l’illusione fenomenica (attribuzione indebita di esperienza soggettiva) e l’illusione morale (attribuzione indebita di competenza etica), che operano su piani distinti, ma presuppongono entrambe il riconoscimento della prima. Chi non ha compreso che l’output è il prodotto di un nucleo stocastico privo di ancoraggio al mondo reale, non dispone neanche degli strumenti critici per cogliere le altre due.
Bibliografia
Chen, E. K., Belkin, M., Bergen, L., & Danks, D. (2026). Does AI already have human-level intelligence? The evidence is clear. Nature, 650(8100), 36–40. https://doi.org/10.1038/d41586-026-00285-6
Dennett, D. C. (1988). The intentional stance in theory and practice. In R. Byrne & A. Whiten (Eds.), Machiavellian intelligence: Social expertise and the evolution of intellect in monkeys, apes, and humans (pp. 180–202). Oxford: Clarendon Press.
Floridi, L., Morley, J., Novelli, C., & Watson, D. (2025). What Kind of Reasoning (if any) is an LLM actually doing? On the Stochastic Nature and Abductive Appearance of Large Language Models. SSRN Scholarly Paper. https://doi.org/10.2139/ssrn.5901962
Harnad, S. (1990). The symbol grounding problem. Physica D: Nonlinear Phenomena, 42(1), 335–346. https://doi.org/10.1016/0167-2789(90)90087-6
Harnad, S. (2025). Language writ large: LLMs, ChatGPT, meaning, and understanding. Frontiers in Artificial Intelligence, 7. https://doi.org/10.3389/frai.2024.1490698
Jones, C. R., & Bergen, B. K. (2025). Large Language Models Pass the Turing Test. arXiv. https://doi.org/10.48550/arXiv.2503.23674
Loru, E., Nudo, J., Di Marco, N., Santirocchi, A., Atzeni, R., Cinelli, M., et al. (2025). The simulation of judgment in LLMs. Proceedings of the National Academy of Sciences, 122(42), e2518443122. https://doi.org/10.1073/pnas.2518443122
Vannacci, A. (2026). AI and the human mind: only one is a black box. Nature, 652(8109), 534. https://doi.org/10.1038/d41586-026-01094-7